Map Reduce and Stream Processing
By
 ·
·
News
·
·
News
Join the DZone community and get the full member experience.
Join For FreeHadoop
Map/Reduce model is very good in processing large amount of data in
parallel. It provides a general partitioning mechanism (based on the
key of the data) to distribute aggregation workload across different
machines. Basically, map/reduce
algorithm design is all about how to select the right key for the
record at different stage of processing.
However, "time dimension" has a very different characteristic compared to other dimensional attributes of data, especially when real-time data processing is concerned. It presents a different set of challenges to the batch oriented, Map/Reduce model.
Here is a more detail description of this high latency characteristic of Hadoop.
Although Hadoop Map/Reduce is designed for batch-oriented work load, certain application, such as fraud detection, ad display, network monitoring requires real-time response for processing large amount of data, have started to looked at various way of tweaking Hadoop to fit in the more real-time processing environment. Here I try to look at some technique to perform low-latency parallel processing based on the Map/Reduce model.
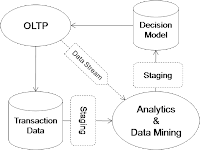 In this
model, data are produced at various OLTP system, which update the
transaction data store and also asynchronously send additional data for
analytic processing. The analytic processing will write the output to a
decision model, which will feed back information to the OLTP system for
real-time decision making.
In this
model, data are produced at various OLTP system, which update the
transaction data store and also asynchronously send additional data for
analytic processing. The analytic processing will write the output to a
decision model, which will feed back information to the OLTP system for
real-time decision making.
Notice the "asynchronous nature" of the analytic processing which is decoupled from the OLTP system, this way the OLTP system won't be slow down waiting for the completion of the analytic processing. Nevetheless, we still need to perform the analytic processing ASAP, otherwise the decision model will not be very useful if it doesn't reflect the current picture of the world. What latency is tolerable is application specific.

One approach is to cut the data into small batches based on time window (e.g. every hour) and submit the data collected in each batch to the Map Reduce job. Staging mechanism is needed such that the OLTP application can continue independent of the analytic processing. A job scheduler is used to regulate the producer and consumer so each of them can proceed independently.
Here lets imagine some possible modification of the Map/Reduce execution model to cater for real-time stream processing. I am not trying to worry about the backward compatibility of Hadoop which is the approach that Hadoop online prototype (HOP) is taking.
Long running
The first modification is to make the mapper and reducer long-running. Therefore, we cannot wait for the end of the map phase before starting the reduce phase as the map phase never ends. This implies the mapper push the data to the reducer once it complete its processing and let the reducer to sort the data. A downside of this approach is that it offers no opportunity to run the combine() function on the map side to reduce the bandwidth utilization. It also shift more workload to the reducer which now needs to do the sorting.
Notice there is a tradeoff between latency and optimization. Optimization requires more data to be accumulated at the source (ie: the Mapper) so local consolidation (ie: combine) can be performed. Unfortunately, low latency requires the data to be sent ASAP so not much accumulation can be done.
HOP suggest an adaptive flow control mechanism such that data is pushed out to reducer ASAP until the reducer is overloaded and push back (using some sort of flow control protocol). Then the mapper will buffer the processed message and perform combine() before it send to the reducer. This approach automatically shift back and forth the aggregation workload between the reducer and the mapper.
Time Window: Slice and Range
This is a "time slice" concept and a "time range" concept. "Slice" defines a time window where result is accumulated before the reduce processing is executed. This is also the minimum amount of data that the mapper should accumulate before sending to the reducer.
"Range" defines the time window where results are aggregated. It can be a landmark window where it has a well-defined starting point, or a jumping window (consider a moving landmark scenario). It can also be a sliding window where is a fixed size window from the current time is aggregated.

After receiving a specific time slice from every mapper, the reducer can start the aggregation processing and combine the result with the previous aggregation result. Slice can be dynamically adjusted based on the amount of data sent from the mapper.
Incremental processing
Notice that the reducer need to compute the aggregated slice value after receive all records of the same slice from all mappers. After that it calls the user-defined merge() function to merge the slice value with the range value. In case the range need to be refreshed (e.g. reaching a jumping window boundary), the init() functin will be called to get a refreshed range value. If the range value need to be updated (when certain slice value falls outside a sliding range), the unmerge() function will be invoked.
Here is an example of how we keep tracked of the average hit rate (ie: total hits per hour) within a 24 hour sliding window with update happens per hour (ie: an one-hour slice).
However, "time dimension" has a very different characteristic compared to other dimensional attributes of data, especially when real-time data processing is concerned. It presents a different set of challenges to the batch oriented, Map/Reduce model.
- Real-time processing demands a very low latency of response, which means there isn't too much data accumulated at the "time" dimension for processing.
- Data collected from multiple sources may not have all arrived at the point of aggregation.
- In the standard model of Map/Reduce, the reduce phase cannot start until the map phase is completed. And all the intermediate data is persisted in the disk before download to the reducer. All these added to significant latency of the processing.
Here is a more detail description of this high latency characteristic of Hadoop.
Although Hadoop Map/Reduce is designed for batch-oriented work load, certain application, such as fraud detection, ad display, network monitoring requires real-time response for processing large amount of data, have started to looked at various way of tweaking Hadoop to fit in the more real-time processing environment. Here I try to look at some technique to perform low-latency parallel processing based on the Map/Reduce model.
General stream processing model
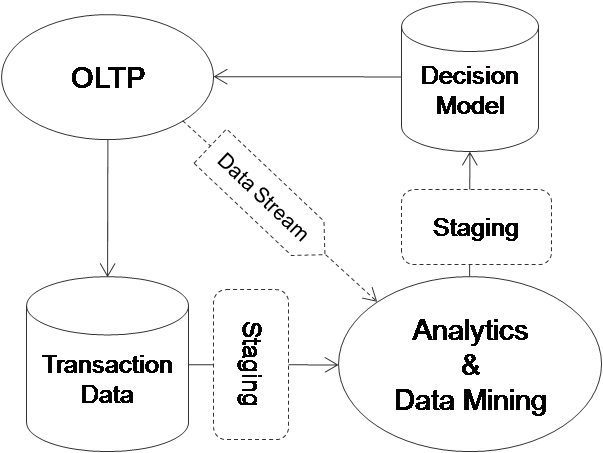 In this
model, data are produced at various OLTP system, which update the
transaction data store and also asynchronously send additional data for
analytic processing. The analytic processing will write the output to a
decision model, which will feed back information to the OLTP system for
real-time decision making.
In this
model, data are produced at various OLTP system, which update the
transaction data store and also asynchronously send additional data for
analytic processing. The analytic processing will write the output to a
decision model, which will feed back information to the OLTP system for
real-time decision making.Notice the "asynchronous nature" of the analytic processing which is decoupled from the OLTP system, this way the OLTP system won't be slow down waiting for the completion of the analytic processing. Nevetheless, we still need to perform the analytic processing ASAP, otherwise the decision model will not be very useful if it doesn't reflect the current picture of the world. What latency is tolerable is application specific.
Micro-batch in Map/Reduce
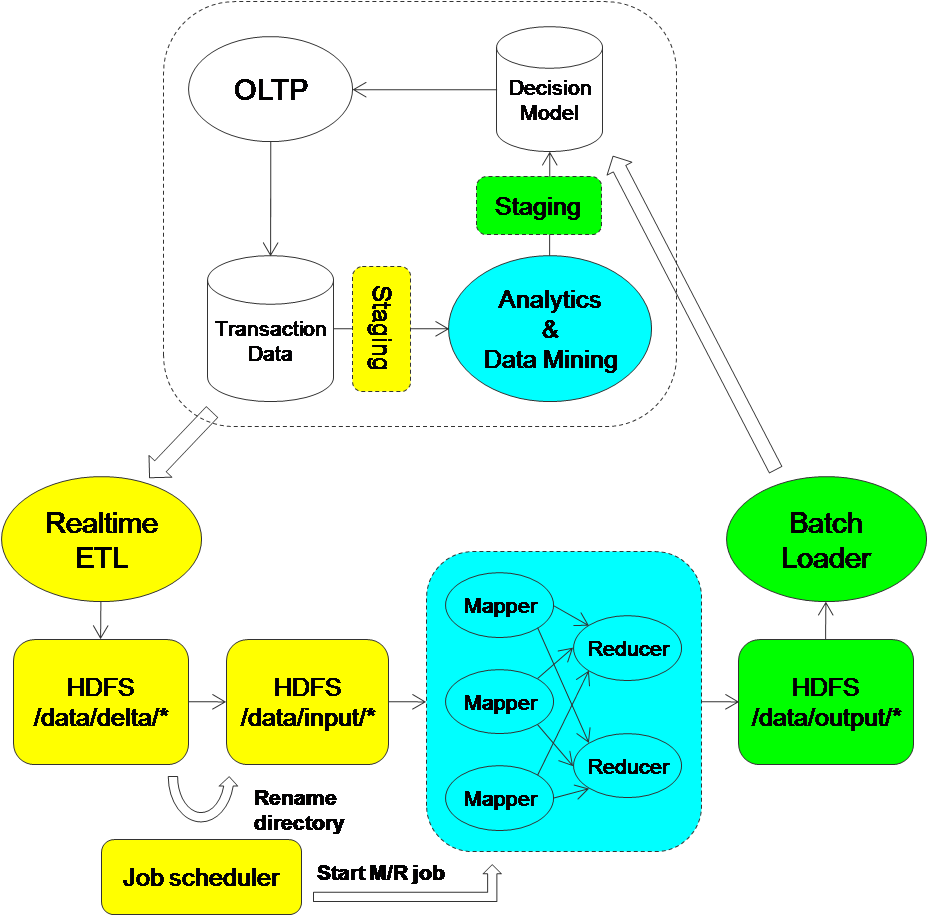
One approach is to cut the data into small batches based on time window (e.g. every hour) and submit the data collected in each batch to the Map Reduce job. Staging mechanism is needed such that the OLTP application can continue independent of the analytic processing. A job scheduler is used to regulate the producer and consumer so each of them can proceed independently.
Continuous Map/Reduce
Here lets imagine some possible modification of the Map/Reduce execution model to cater for real-time stream processing. I am not trying to worry about the backward compatibility of Hadoop which is the approach that Hadoop online prototype (HOP) is taking.
Long running
The first modification is to make the mapper and reducer long-running. Therefore, we cannot wait for the end of the map phase before starting the reduce phase as the map phase never ends. This implies the mapper push the data to the reducer once it complete its processing and let the reducer to sort the data. A downside of this approach is that it offers no opportunity to run the combine() function on the map side to reduce the bandwidth utilization. It also shift more workload to the reducer which now needs to do the sorting.
Notice there is a tradeoff between latency and optimization. Optimization requires more data to be accumulated at the source (ie: the Mapper) so local consolidation (ie: combine) can be performed. Unfortunately, low latency requires the data to be sent ASAP so not much accumulation can be done.
HOP suggest an adaptive flow control mechanism such that data is pushed out to reducer ASAP until the reducer is overloaded and push back (using some sort of flow control protocol). Then the mapper will buffer the processed message and perform combine() before it send to the reducer. This approach automatically shift back and forth the aggregation workload between the reducer and the mapper.
Time Window: Slice and Range
This is a "time slice" concept and a "time range" concept. "Slice" defines a time window where result is accumulated before the reduce processing is executed. This is also the minimum amount of data that the mapper should accumulate before sending to the reducer.
"Range" defines the time window where results are aggregated. It can be a landmark window where it has a well-defined starting point, or a jumping window (consider a moving landmark scenario). It can also be a sliding window where is a fixed size window from the current time is aggregated.

After receiving a specific time slice from every mapper, the reducer can start the aggregation processing and combine the result with the previous aggregation result. Slice can be dynamically adjusted based on the amount of data sent from the mapper.
Incremental processing
Notice that the reducer need to compute the aggregated slice value after receive all records of the same slice from all mappers. After that it calls the user-defined merge() function to merge the slice value with the range value. In case the range need to be refreshed (e.g. reaching a jumping window boundary), the init() functin will be called to get a refreshed range value. If the range value need to be updated (when certain slice value falls outside a sliding range), the unmerge() function will be invoked.
Here is an example of how we keep tracked of the average hit rate (ie: total hits per hour) within a 24 hour sliding window with update happens per hour (ie: an one-hour slice).
# Call at each hit record
map(k1, hitRecord) {
site = hitRecord.site
# lookup the slice of the particular key
slice = lookupSlice(site)
if (slice.time - now > 60.minutes) {
# Notify reducer whole slice of site is sent
advance(site, slice)
slice = lookupSlice(site)
}
emitIntermediate(site, slice, 1)
}
combine(site, slice, countList) {
hitCount = 0
for count in countList {
hitCount += count
}
# Send the message to the downstream node
emitIntermediate(site, slice, hitCount)
}
# Called when reducer receive full slice from all mappers
reduce(site, slice, countList) {
hitCount = 0
for count in countList {
hitCount += count
}
sv = SliceValue.new
sv.hitCount = hitCount
return sv
}
# Called at each jumping window boundary
init(slice) {
rangeValue = RangeValue.new
rangeValue.hitCount = 0
return rangeValue
}
# Called after each reduce()
merge(rangeValue, slice, sliceValue) {
rangeValue.hitCount += sliceValue.hitCount
}
# Called when a slice fall out the sliding window
unmerge(rangeValue, slice, sliceValue) {
rangeValue.hitCount -= sliceValue.hitCount
}
Stream processing
Data processing
Published at DZone with permission of Ricky Ho, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments