Text Processing, Part 2: Oh, Inverted Index
By
 ·
·
Interview
·
·
Interview
Join the DZone community and get the full member experience.
Join For FreeThis is the second part of my text processing series. In this blog, we'll look into how text documents can be stored in a form that can be easily retrieved by a query. I'll used the popular open source Apache Lucene index for illustration.
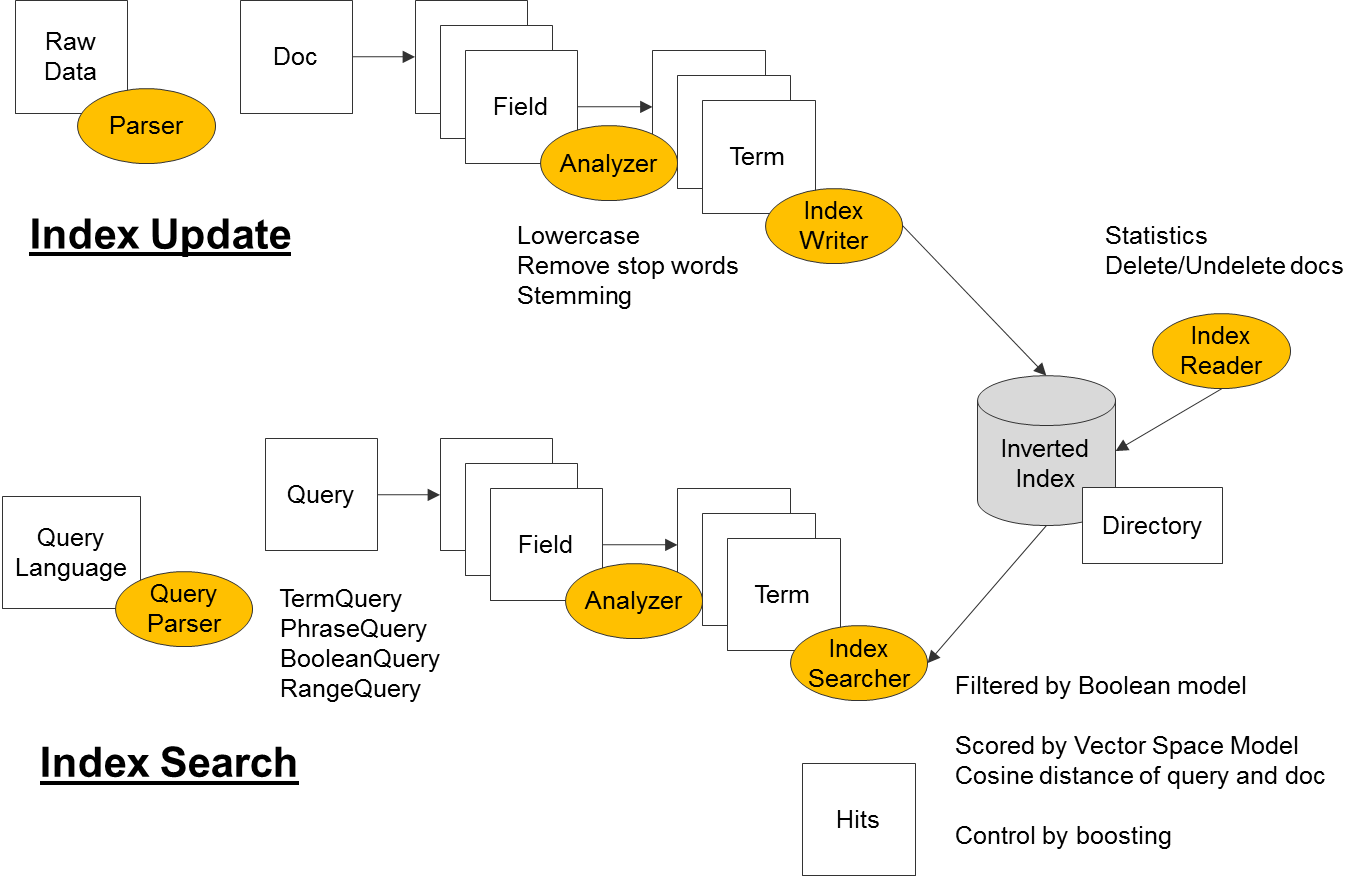
There are two main processing flow in the system ...

To control how the document will be indexed across its containing fields, a Field can be declared in multiple ways to specified whether it should be analyzed (a pre-processing step during index), indexed (participate in the index) or stored (in case it needs to be returned in query result).
This data structure is illustration below based on Lucene's implementation. It is stored on disk as segment files which will be brought to memory during the processing.
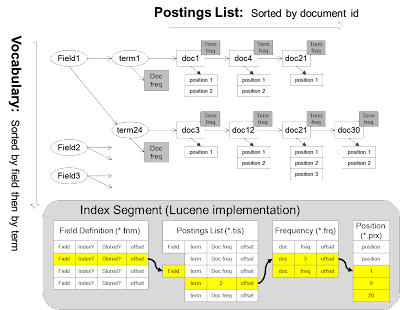
The above diagram only shows the inverted index. The whole index contain an additional forward index as follows.

When the index processing start, it parses each raw document and analyze its text content. The typical steps includes ...
doc1 -> {term1: 5, term2: 8, term3: 4, term1_2: 3, term2_3:1}
We may also compute a "static score" based on some measure of quality of the document. After that, we insert the document into the posting list (if it exist, otherwise create a new posting list) for each terms (all n-grams), this will create the inverted list structure as shown in previous diagram.
There is a boost factor that can be set to the document or field. The boosting factor effectively multiply the term frequency which effectively affecting the importance of the document or field.
Document can be added to the index in one of the following ways; inserted, modified and deleted.
Typically the document will first added to the memory buffer, which is organized as an inverted index in RAM.
As more and more document are inserted into the memory buffer, it will become full and will be flushed to a segment file on disk. In the background, when M segments files have been accumulated, Lucene merges them into bigger segment files. Notice that the size of segment files at each level is exponentially increased (M, M^2, M^3). This maintains the number of segment files that need to be search per query to be at the O(logN) complexity where N is the number of documents in the index. Lucene also provide an explicit "optimize" call that merges all the segment files into one.

Here lets detail a bit on the merging process, since the posting list is already vertically ordered by terms and horizontally ordered by doc id, merging two segment files S1, S2 is basically as follows
tf-idf is a normalized frequency. TF (term frequency) represents how many time the term appears in the document (usually a compression function such as square root or logarithm is applied). IDF is the inverse of document frequency which is used to discount the significance if that term appears in many other documents. There are many variants of TF-IDF but generally it reflects the strength of association of the document (or query) with each term.
Given a query Q containing terms [t1, t2], here is how we fetch the corresponding documents. A common approach is the "document at a time approach" where we traverse the posting list of t1, t2 concurrently (as opposed to the "term at a time" approach where we traverse the whole posting list of t1 before we start the posting list of t2). The traversal process is described as follows ...
Since we have multiple inverted index (in memory buffer as well as the segment files at different levels), we need to combine the result them. If termX appears in both segmentA and segmentB, then the fresher version will be picked. The fresher version is determine as follows; the segment with a lower level (smaller size) will be considered more fresh. If the two segment files are at the same level, then the one with a higher number is more fresh. On the other hand, the IDF value will be the sum of the corresponding IDF of each posting list in the segment file (the value will be slightly off if the same document has been updated, but such discrepancy is negligible). However, the processing of consolidating multiple segment files incur processing overhead in document retrieval. Lucene provide an explicit "optimize" call to merge all segment files into one single file so there is no need to look at multiple segment files during document retrieval.

In document partitioning, documents are randomly spread across different partitions where the index is built. In term partitioning, the terms are spread across different partitions. We'll discuss document partitioning as it is more commonly used. Distributed index is provider by other technologies that is built on Lucene, such as ElasticSearch. A typical setting is as follows ...
In this setting, machines are organized as columns and rows. Each column represent a partition of documents while each row represent a replica of the whole corpus.

During the document indexing, first a row of the machines is randomly selected and will be allocated for building the index. When a new document crawled, a column machine from the selected row is randomly picked to host the document. The document will be sent to this machine where the index is build. The updated index will be later propagated to the other rows of replicas.
During the document retrieval, first a row of replica machines is selected. The client query will then be broadcast to every column machine of the selected row. Each machine will perform the search in its local index and return the TopM elements to the query processor which will consolidate the results before sending back to client. Notice that K/P < M < K, where K is the TopK documents the client expects and P is the number of columns of machines. Notice that M is a parameter that need to be tuned.
One caveat of this distributed index is that as the posting list is split horizontally across partitions, we lost the global view of the IDF value without which the machine is unable to calculate the TF-IDF score. There are two ways to mitigate that ...
- Document indexing: Given a document, add it into the index
- Document retrieval: Given a query, retrieve the most relevant documents from the index.
Index Structure
Both documents and query is represented as a bag of words. In Apache Lucene, "Document" is the basic unit for storage and retrieval. A "Document" contains multiple "Fields" (also call zones). Each "Field" contains multiple "Terms" (equivalent to words).To control how the document will be indexed across its containing fields, a Field can be declared in multiple ways to specified whether it should be analyzed (a pre-processing step during index), indexed (participate in the index) or stored (in case it needs to be returned in query result).
- Keyword (Not analyzed, Indexed, Stored)
- Unindexed (Not analyzed, Not indexed, Stored)
- Unstored (Analyzed, Indexed, Not stored)
- Text (Analyzed, Indexed, Stored)
This data structure is illustration below based on Lucene's implementation. It is stored on disk as segment files which will be brought to memory during the processing.
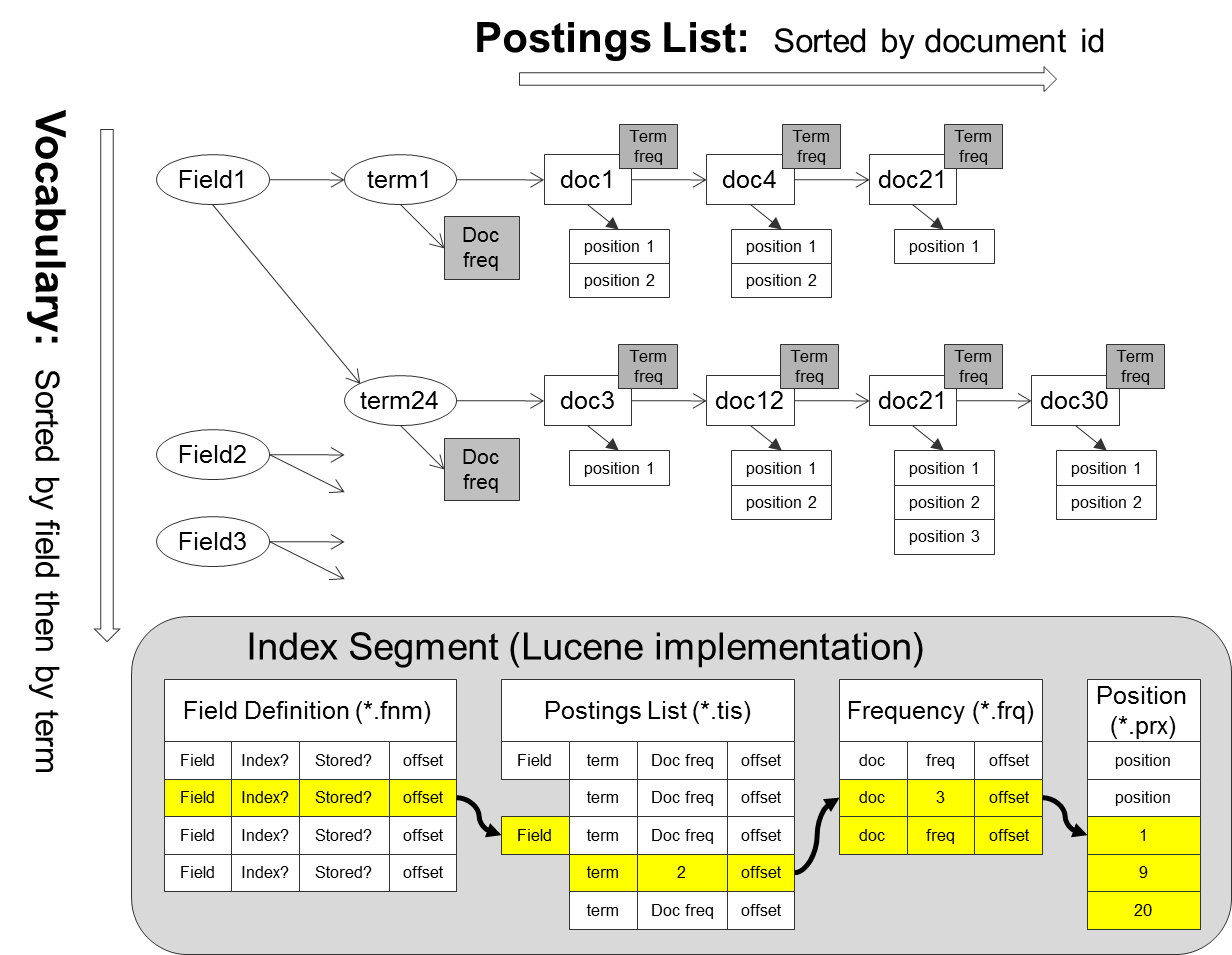
The above diagram only shows the inverted index. The whole index contain an additional forward index as follows.

Document indexing
Document in its raw form is extracted from a data adaptor. (this can be making an Web API to retrieve some text output, or crawl a web page, or receiving an HTTP document upload). This can be done in a batch or online manner.When the index processing start, it parses each raw document and analyze its text content. The typical steps includes ...
- Tokenize the document (breakdown into words)
- Lowercase each word (to make it non-case-sensitive, but need to be careful with names or abbreviations)
- Remove stop words (take out high frequency words like "the", "a", but need to careful with phrases)
- Stemming (normalize different form of the same word, e.g. reduce "run", "running", "ran" into "run")
- Synonym handling. This can be done in two ways. Either expand the term to include its synonyms (ie: if the term is "huge", add "gigantic" and "big"), or reduce the term to a normalized synonym (ie: if the term is "gigantic" or "huge", change it to "big")
doc1 -> {term1: 5, term2: 8, term3: 4, term1_2: 3, term2_3:1}
We may also compute a "static score" based on some measure of quality of the document. After that, we insert the document into the posting list (if it exist, otherwise create a new posting list) for each terms (all n-grams), this will create the inverted list structure as shown in previous diagram.
There is a boost factor that can be set to the document or field. The boosting factor effectively multiply the term frequency which effectively affecting the importance of the document or field.
Document can be added to the index in one of the following ways; inserted, modified and deleted.
Typically the document will first added to the memory buffer, which is organized as an inverted index in RAM.
- When this is a document insertion, it goes through the normal indexing process (as I described above) to analyze the document and build an inverted list in RAM.
- When this is a document deletion (the client request only contains the doc id), it fetches the forward index to extract the document content, then goes through the normal indexing process to analyze the document and build the inverted list. But in this case the doc object in the inverted list is labeled as "deleted".
- When this is a document update (the client request contains the modified document), it is handled as a deletion followed by an insertion, which means the system first fetch the old document from the forward index to build an inverted list with nodes marked "deleted", and then build a new inverted list from the modified document. (e.g. If doc1 = "A B" is update to "A C", then the posting list will be {A:doc1(deleted) -> doc1, B:doc1(deleted), C:doc1}. After collapsing A, the posting list will be {A:doc1, B:doc1(deleted), C:doc1}
As more and more document are inserted into the memory buffer, it will become full and will be flushed to a segment file on disk. In the background, when M segments files have been accumulated, Lucene merges them into bigger segment files. Notice that the size of segment files at each level is exponentially increased (M, M^2, M^3). This maintains the number of segment files that need to be search per query to be at the O(logN) complexity where N is the number of documents in the index. Lucene also provide an explicit "optimize" call that merges all the segment files into one.

Here lets detail a bit on the merging process, since the posting list is already vertically ordered by terms and horizontally ordered by doc id, merging two segment files S1, S2 is basically as follows
- Walk the posting list from both S1 and S2 together in sorted term order. For those non-common terms (term that appears in one of S1 or S2 but not both), write out the posting list to a new segment S3.
- Until we find a common term T, we merge the corresponding posting list from these 2 segments. Since both list are sorted by doc id, we just walk down both posting list to write out the doc object to a new posting list. When both posting lists have the same doc (which is the case when the document is updated or deleted), we pick the latest doc based on time order.
- Finally, the doc frequency of each posting list (of the corresponding term) will be computed.
Document retrieval
Consider a document is a vector (each term as the separated dimension and the corresponding value is the tf-idf value) and the query is also a vector. The document retrieval problem can be defined as finding the top-k most similar document that match a query, where similarity is defined as the dot-product or cosine distance between the document vector and the query vector.tf-idf is a normalized frequency. TF (term frequency) represents how many time the term appears in the document (usually a compression function such as square root or logarithm is applied). IDF is the inverse of document frequency which is used to discount the significance if that term appears in many other documents. There are many variants of TF-IDF but generally it reflects the strength of association of the document (or query) with each term.
Given a query Q containing terms [t1, t2], here is how we fetch the corresponding documents. A common approach is the "document at a time approach" where we traverse the posting list of t1, t2 concurrently (as opposed to the "term at a time" approach where we traverse the whole posting list of t1 before we start the posting list of t2). The traversal process is described as follows ...
- For each term t1, t2 in query, we identify all the corresponding posting lists.
- We walk each posting list concurrently to return a sequence of documents (ordered by doc id). Notice that each return document contains at least one term but can also also contain multiple terms.
- We compute the dynamic score which is dot product of the query to document vector. Notice that we typically don't concern the TF/IDF of the query (which is short and we don't care the frequency of each term). Therefore we can just compute the sum up all the TF score of the posting list that has a match term after dividing the IDF score (at the head of each posting list). Lucene also support query level boosting where a boost factor can be attached to the query terms. The boost factor will multiply the term frequency correspondingly.
- We also look up the static score which is purely based on the document (but not the query). The total score is a linear combination of static and dynamic score.
- Although the score we used in above calculation is based on computing the cosine distance between the query and document, we are not restricted to that. We can plug in any similarity function that make sense to the domain. (e.g. we can use machine learning to train a model to score the similarity between a query and a document).
- After we compute a total score, we insert the document into a heap data structure where the topK scored document is maintained.
- Static Score Posting Order: Notice that the posting list is sorted based on a global order, this global ordering provide a monotonic increasing document id during the traversal that is important to support the "document at a time" traversal because it is impossible to visit the same document again. This global ordering, however, can be quite arbitrary and doesn't have to be the document id. So we can pick the order to be based on the static score (e.g. quality indicator of the document) which is global. The idea is that we traverse the posting list in decreasing magnitude of static score, so we are more likely to visit the document with the higher total score (static + dynamic score).
- Cut frequent terms: We do not traverse the posting list whose term has a low IDF value (ie: the term appears in many documents and therefore the posting list tends to be long). This way we avoid to traverse the long posting list.
- TopR list: For each posting list, we create an extra posting list which contains the top R documents who has the highest TF (term frequency) in the original list. When we perform the search, we perform our search in this topR list instead of the original posting list.
Since we have multiple inverted index (in memory buffer as well as the segment files at different levels), we need to combine the result them. If termX appears in both segmentA and segmentB, then the fresher version will be picked. The fresher version is determine as follows; the segment with a lower level (smaller size) will be considered more fresh. If the two segment files are at the same level, then the one with a higher number is more fresh. On the other hand, the IDF value will be the sum of the corresponding IDF of each posting list in the segment file (the value will be slightly off if the same document has been updated, but such discrepancy is negligible). However, the processing of consolidating multiple segment files incur processing overhead in document retrieval. Lucene provide an explicit "optimize" call to merge all segment files into one single file so there is no need to look at multiple segment files during document retrieval.
Distributed Index
For large corpus (like the web documents), the index is typically distributed across multiple machines. There are two models of distribution: Term partitioning and Document partitioning.
In document partitioning, documents are randomly spread across different partitions where the index is built. In term partitioning, the terms are spread across different partitions. We'll discuss document partitioning as it is more commonly used. Distributed index is provider by other technologies that is built on Lucene, such as ElasticSearch. A typical setting is as follows ...
In this setting, machines are organized as columns and rows. Each column represent a partition of documents while each row represent a replica of the whole corpus.

During the document indexing, first a row of the machines is randomly selected and will be allocated for building the index. When a new document crawled, a column machine from the selected row is randomly picked to host the document. The document will be sent to this machine where the index is build. The updated index will be later propagated to the other rows of replicas.
During the document retrieval, first a row of replica machines is selected. The client query will then be broadcast to every column machine of the selected row. Each machine will perform the search in its local index and return the TopM elements to the query processor which will consolidate the results before sending back to client. Notice that K/P < M < K, where K is the TopK documents the client expects and P is the number of columns of machines. Notice that M is a parameter that need to be tuned.
One caveat of this distributed index is that as the posting list is split horizontally across partitions, we lost the global view of the IDF value without which the machine is unable to calculate the TF-IDF score. There are two ways to mitigate that ...
- Do nothing: here we assume the document are evenly spread across different partitions so the local IDF represents a good ratio of the actual IDF.
- Extra round trip: In the first round, query is broadcasted to every column which returns its local IDF. The query processor will collected all IDF response and compute the sum of the IDF. In the second round, it broadcast the query along with the IDF sum to each column of machines, which will compute the local score based on the IDF sum.
Machine learning
Database
Inverted index
Processing
Data structure
Doc (computing)
Lucene
Published at DZone with permission of Ricky Ho, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments